Revision Update (v0.2): The dataset was cleaned of works not in the public domain in the EU. The
links above follow to the updated versions of data: a separate link to the complete metadata and
the demo dataset.
Since the dataset now includes raw alignments stored in .txt format, it takes up much more disk
space. We will likely use a more compact format, such as .npy, to store these alignments in the
final dataset. In that case, we will also provide a script to unpack the files into a human-readable
format. Another option will be to archive and publish the MIDI data and alignments separately.
We provide the resources to enable reproducibility of our work. The links above contain a demo version of the final PianoCoRe dataset, as well as the source code for our RAScoP refinement pipeline.
Note: The dataset is only provided for the review process and is not available for distribution or use. The separate metadata link includes information on all performances and 5,625 musical pieces. However, to reduce the size of the archive (from 15GB to 1.1GB) for the review process, the dataset is limited to a representative set of up to four performances of each piece from each data source. The unarchived demo dataset takes around 3.3GB of disk space.
The full dataset will be released upon final publication. The data will be archived and distributed on HuggingFace/Zenodo under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0) license to align with the licenses used for the source datasets.
The code release will include a documented RAScoP pipeline and a MIDI quality classifier.
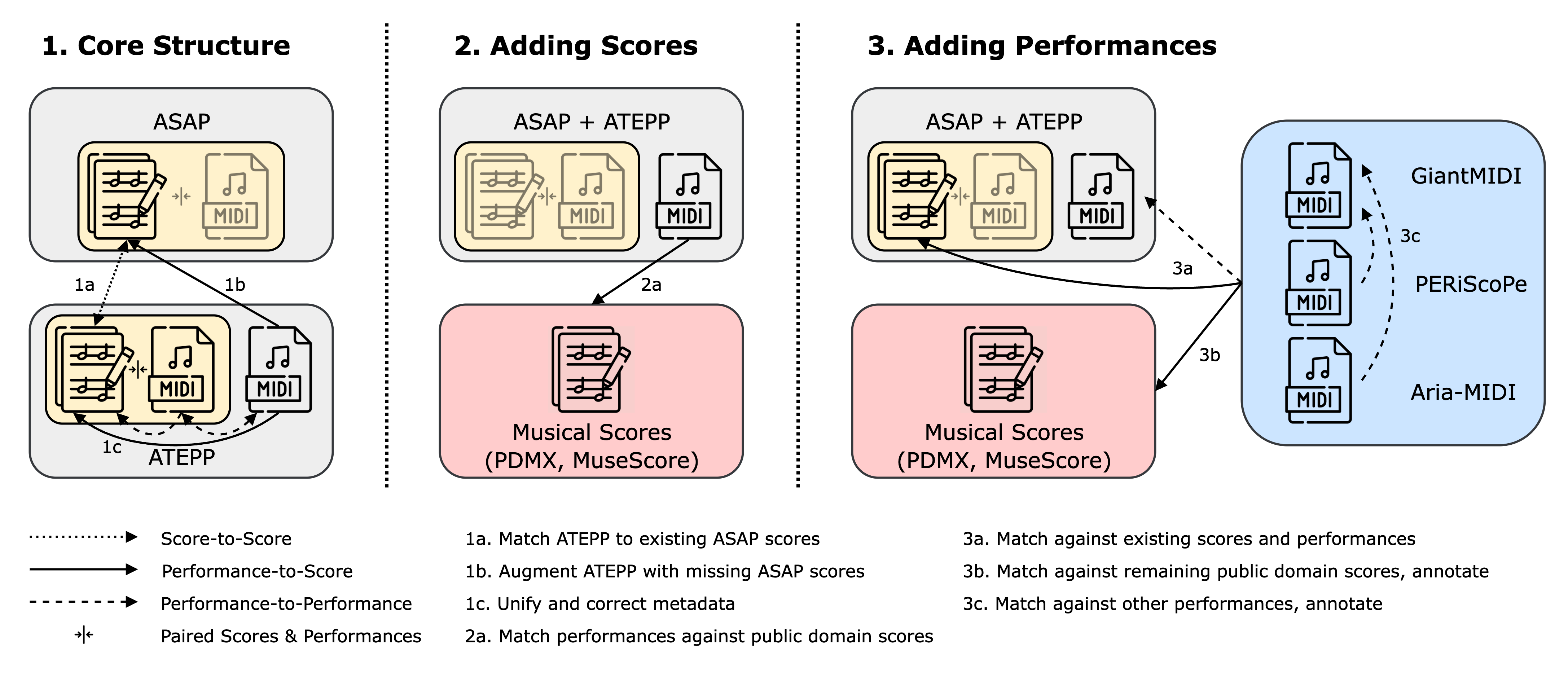
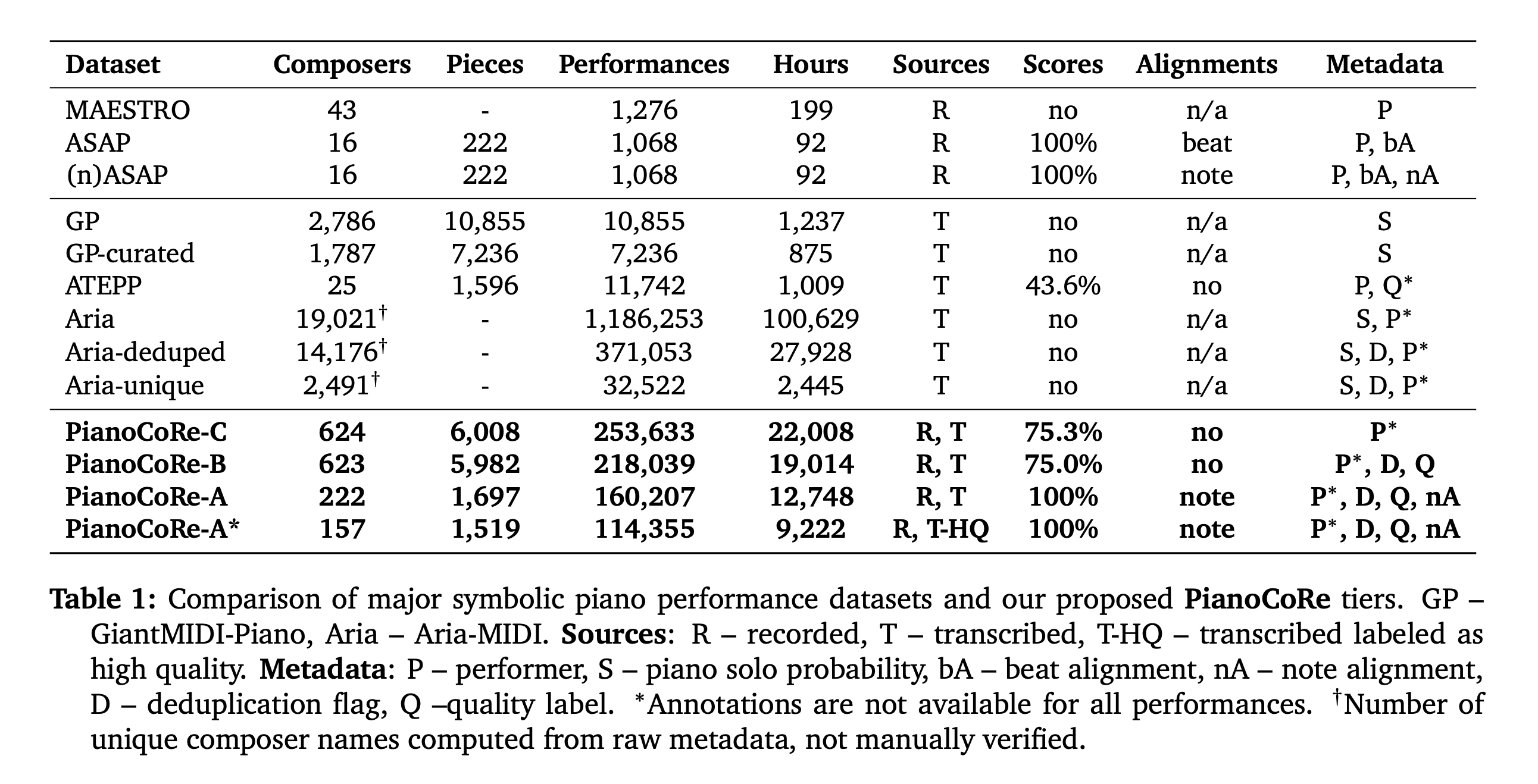
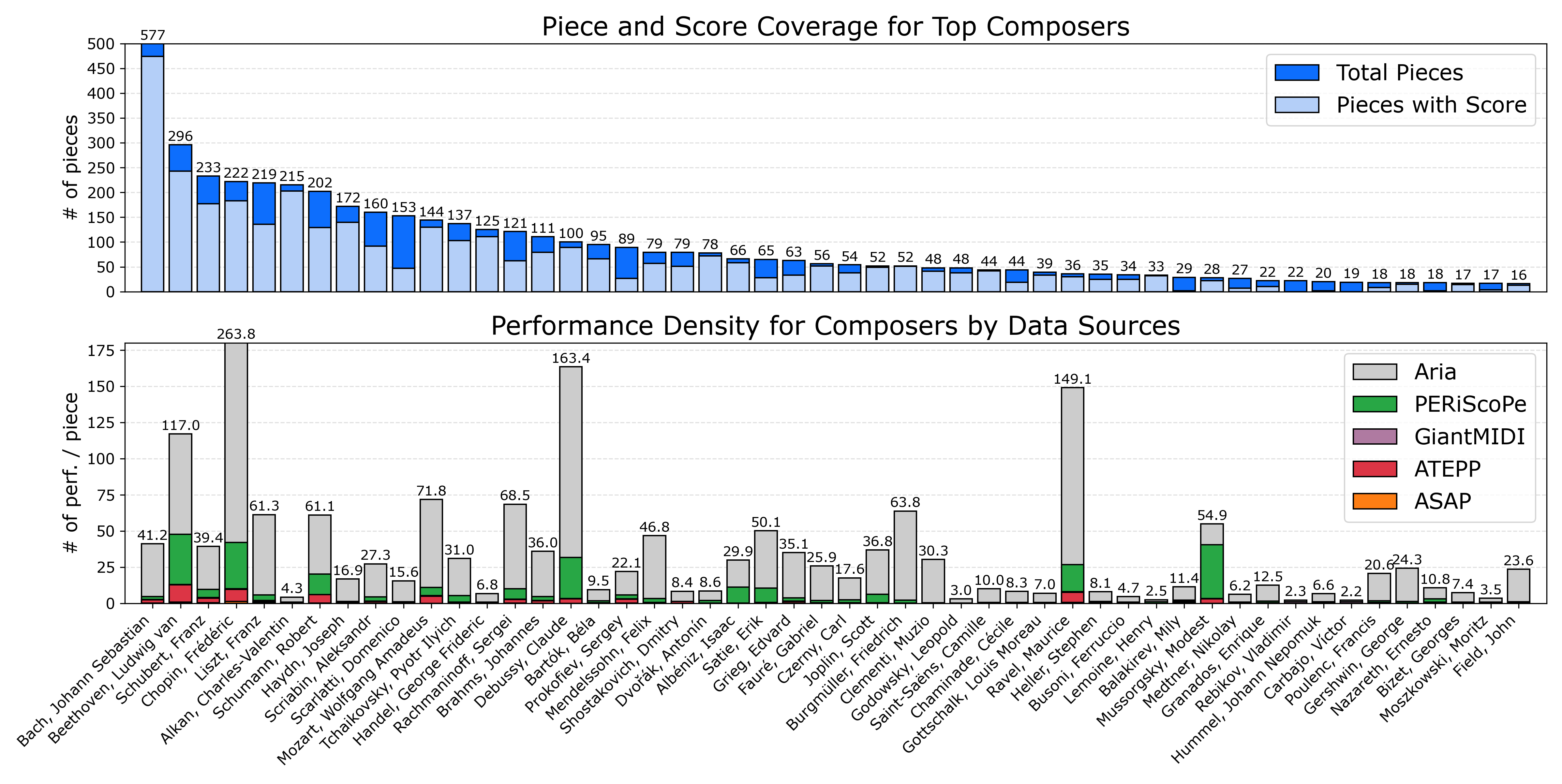
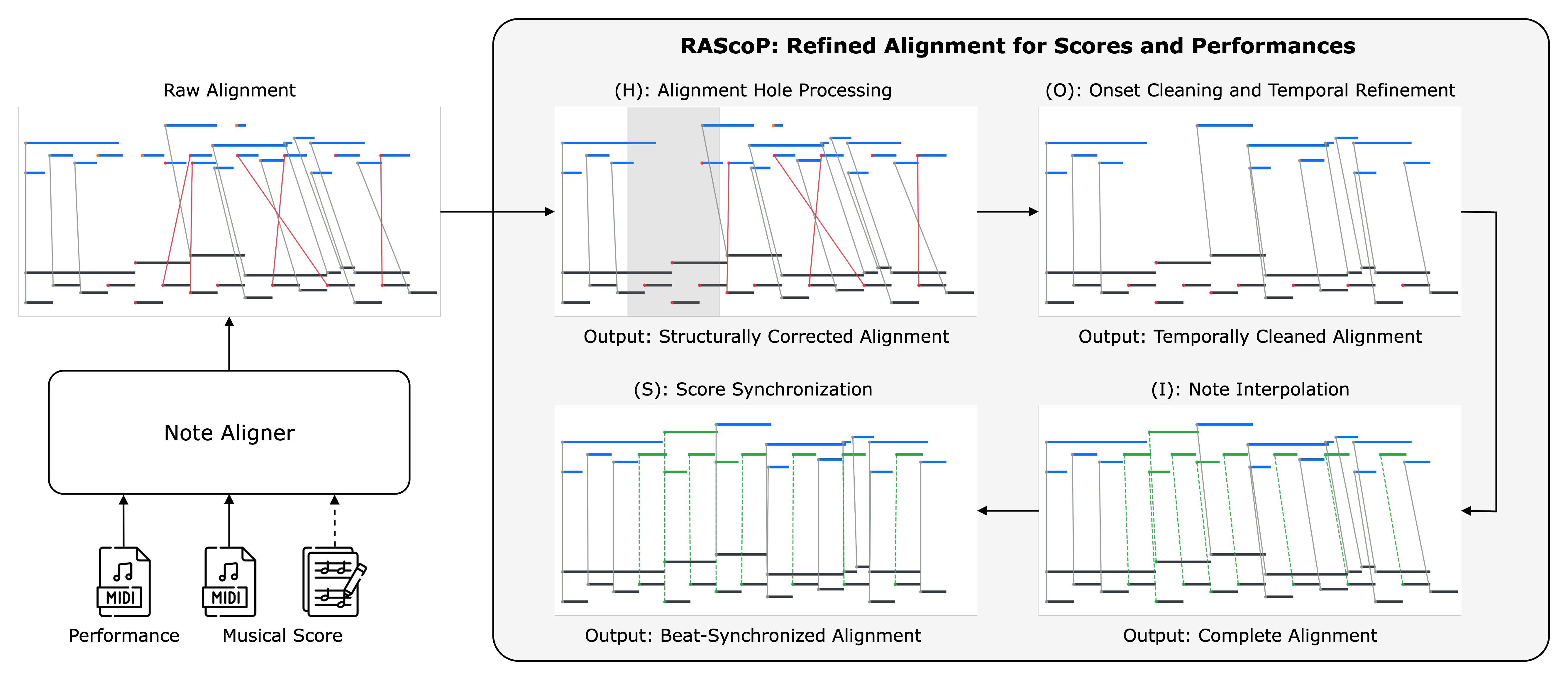
Symbolic music datasets with matched scores and performances are essential for many Music Information Retrieval (MIR) tasks. Yet, existing resources often cover a narrow range of composers, lack performance variety, omit note-level alignments, or use inconsistent naming formats. We present PianoCoRe a large-scale piano MIDI dataset that combines and refines major open-source piano corpora into a unified collection. The dataset contains 250,046 performances of 5,625 pieces written by 483 composers, totaling 21,763 hours of performed music. PianoCoRe is released in tiered subsets to support different applications: from large-scale analysis and pre-training (PianoCoRe-C and deduplicated PianoCoRe-B) to expressive performance modeling with note-level score alignment (PianoCoRe-A/A*). The note-aligned subset, PianoCoRe-A, provides the largest open-source collection of 157,199 performances aligned to 1,591 scores. Apart from the dataset, our contributions include: (1) a MIDI quality classifier for detecting corrupted and score-like transcriptions, and (2) RAScoP, an alignment refinement pipeline that corrects temporal errors and interpolates missing notes. Evaluation shows that the refinement pipeline reduces alignment errors and temporal noise. Moreover, an expressive performance rendering model trained on PianoCoRe demonstrates improved robustness to unseen pieces compared to models trained on raw or smaller datasets. PianoCoRe provides a ready-to-use foundation for the next generation of expressive piano performance research.
@article{anonymous2026pianocore,
author = {Anonymous Authors},
title = {{PianoCoRe}: Combined and Refined Piano {MIDI} Dataset},
journal = {Anonymous Submission},
year = {2026},
}